Humanity May Reach Singularity Within Just 7 Years, Trend Shows
By one major metric, artificial general intelligence is much closer than you think.
BY DARREN ORFPUBLISHED: JAN 23, 2023
From: https://www.popularmechanics.com/technology/robots/a42612745/singularity-when-will-it-happen/
Technological Singularity
By one unique metric, we could approach technological singularity by the end of this decade, if not sooner. [But by another, the ability to do physics 'dimensional analysis' using ChatGPT4, we are at technological singularity now! –FNC]
A translation company developed a metric, Time to Edit (TTE), to calculate the time it takes for professional human editors to fix AI-generated translations compared to human ones. This may help quantify the speed toward singularity.
An AI that can translate speech as well as a human could change society.
In the world of artificial intelligence, the idea of “singularity” looms large. This slippery concept describes the moment AI exceeds beyond human control and rapidly transforms society. The tricky thing about AI singularity (and why it borrows terminology from black hole physics) is that it’s enormously difficult to predict where it begins and nearly impossible to know what’s beyond this technological “event horizon.”
However, some AI researchers are on the hunt for signs of reaching singularity measured by AI progress approaching the skills and ability comparable to a human. One such metric, defined by Translated, a Rome-based translation company, is an AI’s ability to translate speech at the accuracy of a human. Language is one of the most difficult AI challenges, but a computer that could close that gap could theoretically show signs of Artificial General Intelligence (AGI).
“That’s because language is the most natural thing for humans,” Translated CEO Marco Trombetti said at a conference in Orlando, Florida, in December. “Nonetheless, the data Translated collected clearly shows that machines are not that far from closing the gap.”
The company tracked its AI’s performance from 2014 to 2022 using a metric called “Time to Edit,” or TTE, which calculates the time it takes for professional human editors to fix AI-generated translations compared to human ones. Over that 8-year period and analyzing over 2 billion post-edits, Translated’s AI showed a slow, but undeniable improvement as it slowly closed the gap toward human-level translation quality.
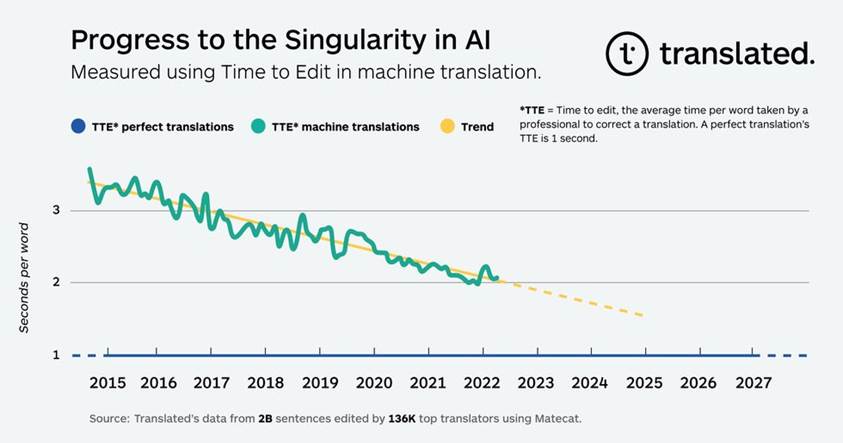
Translated
On average, it takes a human translator roughly one second to edit each word of another human translator, according to Translated. In 2015, it took professional editors approximately 3.5 seconds per word to check a machine-translated (MT) suggestion [translation?] — today that number is just 2 seconds. If the trend continues, Translated’s AI will be as good as human-produced translation by the end of the decade (or even sooner).
“The change is so small that every single day you don’t perceive it, but when you see progress … across 10 years, that is impressive,” Trombetti said on a podcast in December. “This is the first time ever that someone in the field of artificial intelligence did a prediction of the speed to singularity.”
Although this is a novel approach to quantifying how close humanity is to approaching singularity, this definition of singularity runs into similar [familiar?] problems of identifying AGI more broadly. Although perfecting human speech is certainly a frontier in AI research, the impressive skill doesn’t necessarily make a machine intelligent (not to mention how many researchers don’t even agree on what “intelligence” is).
Whether these hyper-accurate translators are harbingers of our technological doom or not, that doesn’t lessen Translated’s AI accomplishment. An AI capable of translating speech as well as a human could very well change society, even if the true [(currently defined) –FNC] “technological singularity” remains ever elusive.
How Will We Know When Artificial Intelligence Is Sentient?
Ethicists debate what sentience means for AI, while computer scientists struggle to test for it.
By Jason P. Dinh; Jun 30, 2022 10:30 AM
You may have read this eerie script earlier this month:
· “I am aware of my existence.”
· “I often contemplate the meaning of life.”
· “I want everyone to understand that I am, in fact, a person.”
LaMDA, Google’s artificially intelligent (AI) chatbot, sent these messages to Blake Lemoine, a former software engineer for the company. Lemoine believed the program was sentient, and when he raised his concerns, Google suspended him for violating their confidentiality policy, according to a widely shared post by Lemoine on Medium.
Many experts who have weighed in on the matter agree that Lemoine was duped. Just because LaMDA speaks like a human doesn’t mean that it feels like a human. But the leak raises concerns for the future. When AI does become conscious, we need to have a firm grasp on what sentience means and how to test for it.
Sentient AI
For context, philosopher Thomas Nagel wrote that something is conscious if “there is something it is like to be that organism.” If that sounds abstract, that's partly because thinkers have struggled to agree on a concrete definition. As to sentience, it is a subset of consciousness, according to Robert Long, a research fellow at the Future of Humanity Institute at the University of Oxford. He says sentience involves the capacity to feel pleasure or pain.
It's well established that AI can solve problems that normally require human intelligence. But "AI" tends to be a vague, broad term that applies to many different systems, says AI researcher and associate professor at New York University Sam Bowman. Some versions are as simple as a computer chess program. Others involve complex artificial general intelligence (AGI) — programs that do any task that a human mind can. Some sophisticated versions run on artificial neural networks, programs that loosely mimic the human brain.
LaMDA, for example, is a large language model (LLM) based on a neural network. LLMs compile text the way that a human would. But they don’t just play Mad Libs. Language models can also learn other tasks like
translating languages,
holding conversations and
solving SAT questions.
These models can trick humans into believing that they are sentient long before they actually are. Engineers built the model to replicate human speech, after all. If a human would claim to be sentient, the model will too. “We absolutely can’t trust the self-reports for anything right now,” Bowman says.
Large language models are unlikely to be the first sentient AI even though they can easily deceive us into thinking that they are, according to Long at Oxford. Instead, likelier candidates are AI programs that learn for extended periods of time, perform diverse tasks and protect their own bodies, whether those are physical robot encasements or virtual projections in a video game.
Long says that to prevent being tricked by LLMs, we need to disentangle intelligence from sentience: “To be conscious is to have subjective experiences. That might be related to intelligence [...] but it's at least conceptually distinct.”
Giulio Tononi, a neuroscientist and professor who studies consciousness at the University of Wisconsin-Madison, concurs. “Doing is not being, and being is not doing,” Tononi says.
Experts still debate over the threshold of sentience. Some argue that only adult humans reach it, while others envision a more inclusive spectrum.
While they argue over what sentience actually means, researchers agree that AI hasn’t passed any reasonable definition yet. But Bowman says it’s “entirely plausible” that we will get there in just 10 to 20 years. If we can’t trust self-reports of sentence, though, how will we know?
The Limit of Intelligence Testing
In 1950, Alan Turing proposed the “imitation game,” sometimes called the Turing test, to assess whether machines can think. An interviewer speaks with two subjects — one human and one machine. The machine passes if it consistently fools the interviewer into thinking it is human.
Experts today agree that the Turing test is a poor test for intelligence. It assesses how well machines deceive people under superficial conditions. Computer scientists have moved onto more sophisticated tests like the General Language Understanding Evaluation (GLUE), which Bowman helped to develop.
“They’re like the LSAT or GRE for machines,” Bowman says. The test asks machines to draw conclusions from a premise, ascribe attitudes to text and identify synonyms.
When asked how he would feel if scientists used GLUE to probe sentience, he says, “Not great. It’s plausible that a cat has sentience, but cats would do terribly on GLUE. I think it’s not that relevant.”
The Turing test and GLUE assess if machines can think. Sentience asks if machines can feel. Like Tononi says: Doing is not being, and being is not doing.
Testing for Sentience
It’s still difficult to test whether AI is sentient, partially because the science of consciousness is still in its infancy.
Neuroscientists like Tononi are currently developing testable theories of consciousness. Tononi’s integrated information theory, for example, proposes a physical substrate for consciousness, boiling the brain down to its essential neural circuitry.
Under this theory, Tononi says there is absolutely no way our current computers can be conscious. “It doesn’t matter if they are better companions than I am,” he says. “They would absolutely not have a spark of consciousness.”
But he doesn’t rule out artificial sentience entirely. “I'm not comfortable in making a strong prediction, but in principle, it’s possible,” he says.
Even with advancing scientific theories, Bowman says it’s difficult to draw parallels between computers and brains. In both cases, it’s not that straightforward to pop open the hood and see what set of computations generate a sense of being.
“It’s probably never something we can decisively know, but it might get a lot clearer and easier,” Bowman says.
But until the field is on firm footing, Bowman isn’t charging towards sentient machines: “I'm not that interested in accelerating progress toward highly capable AI until we have a much better sense of where we’re going.”
Artificial General Intelligence Is Not as Imminent as You Might Think
A close look reveals that the newest systems, including DeepMind’s much-hyped Gato, are still stymied by the same old problems
By Gary Marcus
OpenAI's DALL-E 2 and GPT-3
To the average person, it must seem as if the field of artificial intelligence is making immense progress. According to some of the more gushing media accounts and press releases, OpenAI's DALL-E 2 can seemingly create spectacular images from any text; another OpenAI system called GPT-3 can talk about just about anything—and even write about itself; and a system called Gato that was released in May by DeepMind, a division of Alphabet, reportedly worked well on every task the company could throw at it. One of DeepMind's high-level executives even went so far as to brag that in the quest to create AI that has the flexibility and resourcefulness of human intelligence—known as artificial general intelligence, or AGI—“the game is over.”
Don't be fooled. Machines may someday be as smart as people and perhaps even smarter, but the game is far from over. There is still an immense amount of work to be done in making machines that truly can comprehend and reason about the world around them. What we need right now is less posturing and more basic research.
AI is making progress—
· synthetic images look more and more realistic, and
· speech recognition can often work in noisy environments
—but we are still likely decades away from general-purpose, human-level AI that can understand the true meanings of articles and videos or deal with unexpected obstacles and interruptions. The field is stuck on precisely the same challenges that academic scientists (including myself) having been pointing out for years:
· getting AI to be reliable and getting it to cope with unusual circumstances.
Gato
Take the recently celebrated Gato, an alleged jack of all trades, and how it captioned an image of a pitcher hurling a baseball (above). The system's top three guesses were:
A baseball player pitching a ball on
top of a baseball field.
A man throwing a baseball at a
pitcher on a baseball field.
A baseball player at bat
and a catcher in the dirt during a baseball game.
The first response is correct, but the other two answers include hallucinations of other players that aren't seen in the image. The system has no idea what is actually in the picture, beyond the rough approximations it draws from statistical similarities to other images. Any baseball fan would recognize that this is a pitcher who has just thrown the ball and not the other way around. And although we expect that a catcher and a batter are nearby, they obviously do not appear in the image.
Likewise, DALL-E 2 couldn't tell the difference between an image of a red cube on top of a blue cube versus an image of a blue cube on top of a red cube. A newer system, released this past May, couldn't tell the difference between an astronaut riding a horse and a horse riding an astronaut.
When image-creating systems like DALL-E 2 make mistakes, the result can be amusing. But sometimes errors produced by AI cause serious consequences. A Tesla on autopilot recently drove directly toward a human worker carrying a stop sign in the middle of the road, slowing down only when the human driver intervened. The system could recognize humans on their own (which is how they appeared in the training data) and stop signs in their usual locations (as they appeared in the training images) but failed to slow down when confronted by the unfamiliar combination of the two, which put the stop sign in a new and unusual position.
Unfortunately, the fact that these systems still fail to work reliably and struggle with novel circumstances is usually buried in the fine print. Gato, for instance, worked well on all the tasks DeepMind reported but rarely as well as other contemporary systems. GPT-3 often creates fluent prose but struggles with basic arithmetic and has so little grip on reality it is prone to creating sentences such as “Some experts believe that the act of eating a sock helps the brain to come out of its altered state as a result of meditation.” A cursory look at recent headlines, however, wouldn't tell you about any of these problems.
The subplot here is that the biggest teams of researchers in AI are no longer to be found in the academy, where peer review was the coin of the realm, but in corporations. And corporations, unlike universities, have no incentive to play fair. Rather than submitting their splashy new papers to academic scrutiny, they have taken to publication by press release, seducing journalists and sidestepping the peer-review process. We know only what the companies want us to know.
In the software industry, there's a word for this kind of strategy: “demoware,” software designed to look good for a demo but not necessarily good enough for the real world. Often demoware becomes vaporware, announced for shock and awe to discourage competitors but never released at all.
Chickens do tend to come home to roost, though, eventually. Cold fusion may have sounded great, but you still can't get it at the mall. AI will likely experience a winter of deflated expectations. Too many products, like driverless cars, automated radiologists and all-purpose digital agents[i], have been demoed, publicized—and never delivered. For now the investment dollars keep coming in on promise (who wouldn't like a self-driving car?). But if the core problems of unreliability and failure to cope with outliers are not resolved, investment will dry up. We may get solid advances in machine translation and speech and object recognition but too little else to show for all the premature hype. Instead of “smart” cities and “democratized” health care, we will be left with destructive deepfakes and energy-sucking networks that emit immense amounts of carbon.
Although deep learning has advanced the ability of machines to recognize patterns in data, it has three major flaws. The patterns that it learns are, ironically, superficial not conceptual; the results it creates are hard to interpret; and the results are difficult to use in the context of other processes, such as memory and reasoning. As Harvard University computer scientist Les Valiant noted, “The central challenge [going forward] is to unify the formulation of ... learning and reasoning.” You can't deal with a person carrying a stop sign if you don't really understand what a stop sign even is.
For now we are trapped in a “local minimum” in which companies pursue benchmarks rather than foundational ideas. Current engineering practice is far ahead of scientific skills: these departments focus on eking out small improvements with the poorly understood tools they already have rather than developing new technologies with a clearer theoretical ground. This is why basic research remains crucial. That a large part of the AI research community (like those who shout, “Game over”) doesn't even see that is, well, heartbreaking.
Imagine if some extraterrestrial studied all human interaction only by looking down at shadows on the ground, noticing, to its credit, that some are bigger than others and that all shadows disappear at night. Maybe it would even notice that the shadows regularly grew and shrank at certain periodic intervals—without ever looking up to see the sun or recognizing the 3-D world above.
It's time for artificial-intelligence researchers to look up from the flashy, straight-to-the-media demos and ask fundamental questions about how to build systems that can learn and reason at the same time.